
当我们执行如下操作时:
HashMap<String, Float> map = new HashMap<String, Float>();
map.put("语文", 86.5f);
map.put("数学", 93.0f);
map.put("英语", 90.0f);
对于HashMap而言,采用一种所谓的“Hash算法”来决定每个元素的存储位置。当程序执行 map.put(“语文”, 86.5f);时,系统将调用”语文”的 hashCode() 方法得到其 hashCode值, 每个Java对象都有 hashCode() 方法,都可通过该方法或得它的 hashCode 值。得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置。
HashMap存储结构图
HashMap采取数组加链表的存储方式来实现。亦即数组(散列桶)中的每一个元素都是链表,如下图:
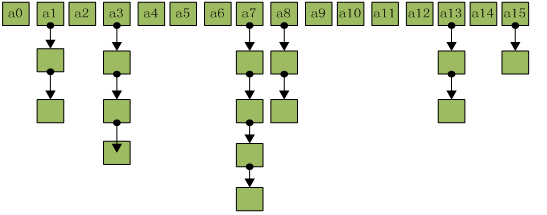
说明:下面针对 HashMap 的源码分析中,所有提到的桶或散列桶都表示存储结构中数组的元素,桶或散列桶的数量亦即表示数组的长度,哈希码亦即散列码。
PS:以下源码基于JDK1.7
HashMap类的put(K key, V value)方法的源代码如下。
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//如果key为null,调用putForNullKey方法进行处理
if (key == null)
return putForNullKey(value);
//根据key计算Hash值
int hash = hash(key);
//搜索指定hash值在对应table中的索引
int i = indexFor(hash, table.length);
//如果i索引处的Entry不为null,通过循环不断遍历e元素的下一个元素
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//找到指定key与需要放入的key相等(hash值相同,通过equals比较放回true)
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//如果i索引处的Entry为null,表明此处还没有Entry
modCount++;
//将key、value添加到i索引处
addEntry(hash, key, value, i);
return null;
}
上面程序中用到了一个重要的内部接口 Map.Entry, 每个 Map.Entry 其实就是一个 key-value 对。从上面程序中可以看出:当系统决定存储 HashMap 中的 key-value 对时,完全没有考虑Entry中的value,而仅仅只是根据key来计算并决定每个Entry的存储位置。
从上面put方法的源码可以看出,当程序试图将一个key-value对放入HashMap中时,首先根据该key的hashCode()返回值决定该Entry的存储位置:如果两个Entry的key的hashCode()返回值相同,那它们的存储位置相同;如果这两个Entry的key通过equals比较返回true,新添加Entry的value将覆盖集合中原有Entry的value,但key不会覆盖;如果这两个Entry的key通过equals比较返回false,新添加的Entry将与集合中原有Entry形成Entry链,而且新添加的Entry位于Entry链的头部
当向HashMap中添加key-value对,由其key的hashCode()返回值决定该key-value对(就是Entry对象)的存储位置。当两个Entry对象的key的hashCode()返回值相同时,将由key通过equals()比较值决定是采用覆盖行为(返回true),还是产生Entry链(返回false)
上面程序中还调用了 addEntry(hash, key, value, i) 方法
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果Map中的key-value对的数量超过了极限 并且bucketIndex索引处的table不为null
if ((size >= threshold) && (null != table[bucketIndex])) {
//把table对象的长度扩容2倍
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
上面程序中还有以下两个变量。
size:该变量保存了该HashMap中所包含的key-value对的数量threshold: 该变量包含了HashMap能容纳的key-value对的极限,它的值等于HashMap的容量乘以负载因子(load factor)
从上面程序代码中可以看出,当size >= threshold时,HashMap会自动调用resize方法扩充HashMap的容量,每扩充一次,HashMap的容量就增大一倍。
上面程序中使用的table其实就是一个普通数组,每个数组都有一个固定的长度,这个数组的长度就是HashMap的容量。HashMap包含如下几个构造器。
HashMap(): 构建一个初始容量为16,负载因子为0.75的HashMapHashMap(int initialCapacity):构建一个初始容量为initialCapacity,负载因子为0.75的HashMapHashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个HashMap
当创建一个HashMap时,系统会自动创建一个table数组来保存HashMap的Entry。下面是HashMap中一个构造器的代码。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity; //① 计算阈值,这句是重点
init();
}
上面①处代码是直接使用了初始大小作为阈值的大小,而在JDK1.6中就完全不一样
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor); // 计算阈值 JDK1.6
table = new Entry[capacity];
init();
}
代码片段
threshold = (int)(capacity * loadFactor);
这是阈值的计算公式,其中capacity(容量)的缺省值为16,loadFactor(负载因子)缺省值为0.75,那么
threshold = (int)(16 * 0.75) = 12
对于HashMap及其子类而言,它们采用Hash算法来决定集合中元素的存储位置。当系统开始初始化HashMap时,系统会创建一个长度为capacity的Entry数组。这个数组里可以存储元素的位置被称为”桶(bucket)”,每个bucket都有其指定索引,系统可以根据其索引快速访问该bucket里存储的元素。
无论何时,HashMap的每个”桶”只存储一个元素(即一个Entry)。由于Entry对象可以包含一个引用变量(就是Entry构造器的最后一个参数)用于指向下一个Entry,因此可能出现:HashMap的bucket中只有一个Entry,但这个Entry指向零一个Entry,这就形成了一个Entry链
当HashMap的每个bucket里存储的Entry只是单个Entry,即没有通过指针产生Entry键时,此时的HashMap具有最好的性能。当程序通过key取出对应value时,系统只要先计算出该key的hashCode()返回值,再根据该hashCode返回值找出该key再table数组中的索引,然后取出该索引处的Entry,最后返回该key对应的value。
HashMap类的get(K key)方法代码如下。
public V get(Object key) {
//如果key时null,调用getForNullKey取出对应的value
if (key == null)
return getForNullKey();
//调用getEntry()方法
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//根据key的hashCode值计算它的hash码
int hash = (key == null) ? 0 : hash(key);
//直接取出table数组中指定索引处的值
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
//搜索该Entry链的下一个Entry
e = e.next) {
Object k;
//如果该Entry的key与被搜索key相同,返回对应的value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
HashMap在底层将key-value当成一个整体进行处理,这个整体就是一个Entry对象。HashMap底层采用一个Entry[]数组来保存所有的key-value对,当需要存储一个Entry对象时,会根据Hash算法来决定其存储位置;当需要取出一个Entry时,也会根据Hash算法找到其存储位置,直接取出该Entry。由此可见,HashMap之所以能快速存、取它所包含的Entry,完全类似于现实生活中的:不同的东西要放在不同的位置,需要时才能快速找到它。
当创建HashMap时,有一个默认的负载因子(load factor),其默认值为0.75 。这是时间和空间成本上的一种折中:增大负载因子可以减少Hash表(就是那个Entry数组)所占用的内存空间,但会增加查询数据的时间开销,而查询时最频繁的操作,减小负载因子会提高数据查询的性能,但会降低Hash表所占用的内存空间。
